Abstract
Open-world generalization requires robotic systems to have a profound understanding of the physical world and the user command to solve diverse and complex tasks. While the recent advancement in vision-language models (VLMs) has offered unprecedented opportunities to solve open-world problems, how to leverage their capabilities to control robots remains a grand challenge. In this paper, we introduce Marking Open-world Keypoint Affordances (MOKA), an approach that employs VLMs to solve robotic manipulation tasks specified by free-form language instructions. Central to our approach is a compact point-based representation of affordance, which bridges the VLM’s predictions on observed images and the robot’s actions in the physical world. By prompting the pre-trained VLM, our approach utilizes the VLM’s commonsense knowledge and concept understanding acquired from broad data sources to predict affordances and generate motions. To facilitate the VLM’s reasoning in zero-shot and few-shot manners, we propose a visual prompting technique that annotates marks on images, converting affordance reasoning into a series of visual question-answering problems that are solvable by the VLM. We further explore methods to enhance performance with robot experiences collected by MOKA through in-context learning and policy distillation. We evaluate and analyze MOKA’s performance on various table-top manipulation tasks including tool use, deformable body manipulation, and object rearrangement.
Marking Open-world Keypoint Affordances (MOKA)
MOKA employs VLMs in a hierarchical visual prompting framework, which converts the affordance reasoning problem into a series of visual question problems that are feasible for the VLM to address.
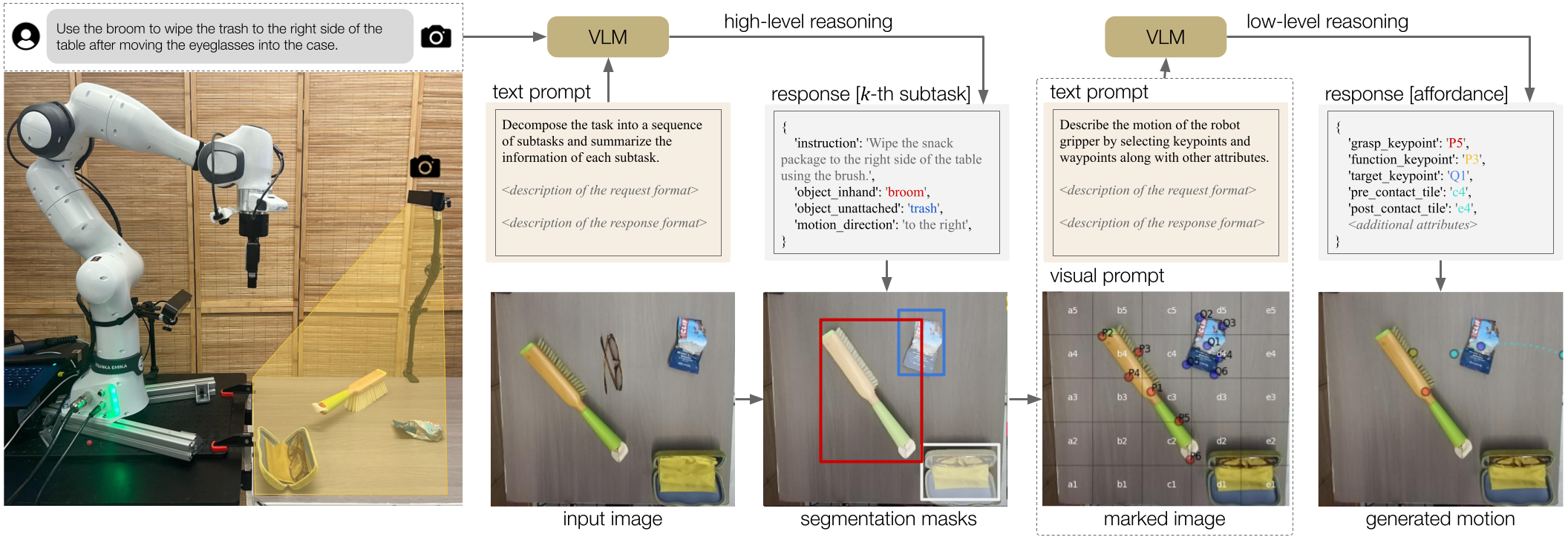
On the high level, the VLM is prompted to decompose the free-form language description of the task into a sequence of subtasks and summarize the subtask information. On the low level, the VLM produces the point-based affordance representation based on the marked image.
Point-based Affordance Representations
To bridge the VLM’s predictions on 2D images and the robot’s motion in the physical world, we introduce a point-based affordance representation. Using a set of keypoints and waypoints, we can specify the robot’s motions for a wide range of tasks.

Tasks
Given free-form descriptions of the tasks, MOKA can effectively predict the point-based affordance representations and generates the desired motions.
"Move the eyeglasses onto the yellow cloth and use the brush to sweep the snack package to the right side of the table."
(Subtask 1)
"Use the ultrasound cleaner to clean the metal watch. The unstrasound cleaner has no lid and can be turned on by pressing the red button."
(Subtask 1)
"Close the drawer."
"Move the eyeglasses onto the yellow cloth and use the brush to sweep the snack package to the right side of the table."
(Subtask 2)
"Use the ultrasound cleaner to clean the metal watch. The unstrasound cleaner has no lid and can be turned on by pressing the red button."
(Subtask 2)
"Insert the pink roses into the vase."
"Make a gift box containing the perfurme bottle. Put some golden filler beneath the perfume."
(Subtask 1)
"Unplug the charge cable and close the lid of the laptop."
(Subtask 1)
"Use the fur remover to remove the white fur ball on the sweater."
"Make a gift box containing the perfurme bottle. Put some golden filler beneath the perfume."
(Subtask 2)
"Unplug the charge cable and close the lid of the laptop."
(Subtask 2)
"Put the scissors in the hand."
Robustness Analysis
For the same task, MOKA's prediction is robust to variations of instructions, objects, and initial poses. Each column in the image uses the same language instruction and similar initial arrangements of objects. The two rows involve different objects.



BibTeX
@article{fangandliu2024moka,
title={MOKA: Open-World Robotic Manipulation through Mark-Based Visual Prompting},
author={Kuan Fang and Fangchen Liu and Pieter Abbeel and Sergey Levine},
journal={Robotics: Science and Systems (RSS)},
year={2024}
}